
 SEO优化
SEO优化  搜索引擎SEO
搜索引擎SEO 防范6种负面SEO攻击与保护网站排名!
尽管负面SEO的威胁可能听起来遥远且让人不安,但了解如何保护您的网站免受这种潜在的破坏至关重要。在我们探讨具体的防御措施之前,首先明确什么是负面SEO,以及它通常不是导致排名下降的原因。
负面SEO指的是一系列策略,其目的是降低竞争对手在搜索引擎结果页(SERPs)上的排名。这些恶意行为通常发生在您的网站之外,例如,通过创建大量不自然的反向链接指向您的网站,或者复制您的内容并在其他地方发布。在某些极端情况下,它们甚至可能包括黑客攻击,通过修改您网站的内容来伤害您的SEO表现。
然而,负面SEO并不总是导致排名下降的主要原因。在确定您的网站可能遭受有意的SEO破坏之前,请先排查其他更常见的排名下降原因,例如网站优化不当、Google算法更新或技术问题。您可以在这里查看关于排名下降的更全面解释。
现在,让我们看看需要警惕的六种负面SEO策略:
一、负面站外 SEO
1、链接农场
零星的几个垃圾链接通常对网站排名无害。然而,负面SEO攻击往往涉及大量从互相关联的网站网络或所谓的“链接农场”中生成的链接。这些链接通常采用相同的锚文本,它们要么与被攻击网站完全不相关,要么包含特定的利基关键词,使得目标网站的链接配置文件看起来像是有意为之的操纵。
以WordPress播客网站WP Bacon为例,该网站在短时间内收到了数以千计带有“***”锚文本的链接。结果,WP Bacon在Google上的大多数关键词排名在10天内下降了50多位。幸运的是,网站管理员及时采取行动拒绝了这些垃圾链接,最终网站排名得到了恢复。
如何保护自己:
虽然无法完全避免负面SEO攻击,但及早发现并采取行动可以最小化损害。为此,您需要定期监控您的链接概况。
例如,SEO SpyGlass可以展示您的链接数量和引用域数量随时间的变化。任何异常的峰值都可能是攻击迹象。要查看具体的链接,您可以在SEO SpyGlass的反向链接面板中按发现日期排序,找到与峰值对应的链接。
如果您不确定链接的来源,评估其潜在的惩罚风险是有帮助的。在“链接惩罚风险”选项卡中,选中可疑的链接并更新其惩罚风险值。这个指标会考虑多个因素,包括是否有大量链接来自同一IP地址或C类地址。
一旦确定了垃圾链接,您可以在SEO SpyGlass中创建一个拒绝文件。右键点击要拒绝的链接或域名,选择“创建拒绝文件”,并确保在“拒绝模式”下选择“拒绝整个域”。对所有可疑链接重复此操作。完成后,进入“首选项”>“拒绝/黑名单反向链接”,审查您的拒绝文件,并在确认无误后导出并提交给Google。
2、应对内容刮取的策略
内容刮取是一种常见的负面SEO手段,竞争对手通过这种方式抓取并复制您的内容到其他网站,以此来破坏您的搜索排名。当Google检测到多个网站上有相同的内容时,它通常只会对其中一个版本进行索引和排名。尽管大多数时候Google能够辨识出原创内容,但如果搜索引擎先发现的是复制的版本,原创内容的排名就可能受到影响。这也是为什么刮取工具会迅速抓取新内容并立即发布的原因。
如何保护您的内容:
若要查找被复制内容的实例,Copyscape是一个极佳的资源。一旦您发现了自己内容的未经授权副本,首先应该尝试联系对方网站的管理员,要求他们移除侵权内容。如果对方不予理会,您可以向Google提交版权侵权投诉。
3、抵御恶意爬虫攻击
在SEO竞争中,一些网站所有者可能会采取极端措施,通过对竞争对手网站进行频繁且密集的爬取,从而增加服务器压力,导致网站性能下降甚至崩溃。如果Google的爬虫程序(Googlebot)在尝试访问您的网站时连续多次失败,您的网站排名可能会因此受到负面影响。
如何确保网站安全:
如果您注意到网站响应变慢或者出现无法访问的情况,您应立即联系您的托管服务提供商或网站管理员。他们能帮助您确定流量是否异常以及这些流量的来源。如果您对服务器日志有所了解,以下是一些步骤,帮助您识别恶意爬虫,并利用robots.txt和.htaccess文件来阻止它们:
①检查服务器日志,找出请求频率异常高的IP地址。
②使用robots.txt文件指示合法的爬虫减少爬取频率。
③对于恶意爬虫,可以在.htaccess文件中设置规则,根据IP地址或User-Agent来阻止它们的访问。
二、防范负面页面SEO攻击
负面页面SEO攻击虽然实施难度较大,但一旦发生,其对网站的影响可能是毁灭性的。这类攻击通常涉及黑客侵入网站后台,对网站的内容和结构进行恶意修改。
1、防范内容篡改与恶意重定向
您可能会认为,如果网站内容遭到更改,您能立即察觉。然而,不幸的是,这些变更有时候可能非常隐蔽,以至于很难被及时发现。攻击者可能会在您的网站中添加垃圾内容,如隐形链接,这些内容通常会被巧妙地隐藏起来(比如,通过在HTML中设置display: none),使得这些变更在不检查网页源代码的情况下不被看见。
在更为复杂的负面SEO攻击情况下,攻击者可能会修改您的网页代码,使之重定向到他们自己的网站。这对于大多数小型企业来说可能不是一个直接的威胁,但对于那些拥有高权威性和高链接流行度的网站来说,这可能被用作一种悄无声息地提升攻击者自己网站PageRank的手段,或者是在用户尝试访问您的网站时,将他们重定向到攻击者的网站。对于被攻击的网站而言,这种重定向远不止是一个临时的不便。如果谷歌先于您发现了这些重定向行为,您的网站可能会因“将用户重定向到恶意网站”而遭受惩罚。
保护您的网站安全的策略:
·定期网站审计:使用如WebSite Auditor这样的工具进行定期的网站审计是检测这类隐蔽攻击的有效方法。要开始首次审计,仅需在WebSite Auditor中为您的网站创建一个项目。通过定期点击“重建项目”按钮来重新运行审计,您将能及时发现和纠正那些可能被忽略的修改,比如网站上新增的传出链接数量或带有重定向的页面。
·检查外部资源:在“所有资源”仪表板中,您可以查看“外部资源”部分,详细了解这些新增的链接或重定向。若发现外部链接数量异常增加,您可以在列表中查看这些链接的目标地址,并在页面底部找到含有这些链接的具体页面位置。
2、维护网站索引的完整性
在SEO实践中,robots.txt文件的重要性不容忽视,因为它指导着搜索引擎爬虫如何与您的网站互动。一个微小的错误,比如错误地添加了一条Disallow: /规则,就足以让Google爬虫忽略您网站上的所有内容,从而对您的SEO战略造成灾难性的影响。
有众多案例证明了这一点,其中一个显著的故事发生在一位客户身上。在解雇了一家他们不满意的SEO代理机构后,作为报复,该机构在客户的robots.txt文件中添加了一条Disallow: /规则,导致网站被Google完全忽略。
如何确保网站保持索引:
为了防止您的网站被无意中取消索引,您应该定期进行排名监控。借助排名跟踪工具,您可以设置日常或周常的自动检查。如果您的网站排名突然从搜索引擎结果页面(SERP)消失,您将在排名变化报告中看到“已删除”的标记。
当这种现象在众多关键词上同时发生时,这通常是网站遭受了惩罚或被取消索引的迹象。在这种情况下,您应立即访问Google Search Console,查看网站的抓取统计数据,同时仔细检查您的robots.txt文件,确保没有被不当修改。
3、黑客攻击网站
黑客攻击对网站的损害远远超出了瞬间的破坏——它们对您的搜索引擎排名同样具有潜在的长期影响。搜索引擎巨头如谷歌,其核心使命之一就是确保用户在网上的安全。因此,当谷歌检测到一个网站可能遭受黑客攻击时,它会采取措施保护用户,包括在搜索结果中对该网站标注警告,或者降低其在搜索结果中的排名。这样的警告可能会表述为“此网站可能被黑客攻击”,这显然会让潜在访问者犹豫是否点击。
如何确保您的网站安全:
在SEO策略中,网站安全是一个不可忽视的核心要素。以下是一些基本的安全措施,可帮助确保您的网站不受黑客攻击,从而维护您的搜索引擎排名:
·及时更新软件:保持所有网站平台、插件和主题的更新,以利用最新的安全补丁。
·使用复杂密码:为所有账户设置强大的密码,并定期更新。
·权限管理:只授予必要的用户权限,避免不必要的高权限账号存在。
·定期备份:创建网站和数据库的定期备份,以便在遭遇黑客攻击时能够快速恢复。
·安全插件:安装和使用安全插件或服务,如Web应用防火墙(WAF)和恶意软件扫描。
·启用SSL证书:确保网站使用HTTPS,为用户提供安全的连接。
·监控活动:设置监控系统,跟踪网站活动,及时发现和响应异常行为。
·教育团队:对团队成员进行网络安全培训,提高他们对网络威胁的认识。
网站的安全性不仅仅是为了防止黑客攻击,也是为了维护网站的信誉和搜索引擎排名。通过实施上述措施,您可以为网站构建一道防线,保护它免受攻击,同时也保护您的SEO努力不受影响。更深入的安全策略和建议,您可以通过专业的网络安全资源来获取。
上一篇:SEO的力量:29个需要搜索引擎优化原因!
SEO就是搜索引擎优化:让你的网站在搜索引擎(比如百度、谷歌)的排名更靠前,当用户通过关键词搜索时更容易搜到你的网站,从而实现企业品牌曝光、主动获客和营销推广的目标。
为什么要做SEO?
提高网站访问量:SEO能让你的网站在搜索引擎结果中更靠前,吸引更多客户点击。
降低市场营销成本:相比于付费广告,SEO是一种更经济有效的营销方式。
提升品牌知名度:网站排名靠前,可以让更多用户看到你的品牌名称和信息,增强品牌影响力。
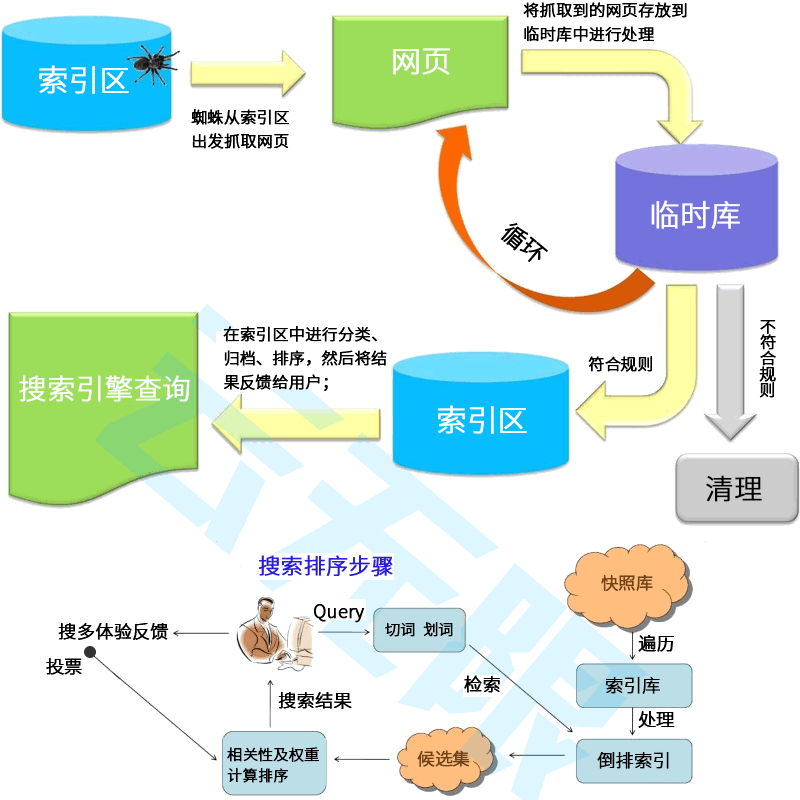 SEO优化有哪些优势?
SEO优化有哪些优势?
成本低廉:主要成本是优化师的工资。
效果稳定:一旦网站排名上升,效果稳定持久,可持续获得展现机会。
不受地域限制:SEO的效果可以覆盖全球,不受时间和空间的限制。
什么样的公司更适合做SEO优化呢?大多数行业都可以从SEO中受益。特别是那些希望用户主动访问我们的网站、降低营销成本、提升品牌知名度的企业。通过SEO来优化自己的网站,可吸引更多潜在客户。
SEO是一种工人的有效的网络营销手段,可以帮助企业提升关键词排名,吸引更多用户,实现商业目标。SEO是一个长期且专业的技术,企业在进行SEO时,必须耐心优化,因为SEO涉及到的不止是网站结构、内容质量、用户体验、外部链接这几个方面;还有算法的更替、蜘蛛的引导、快照的更新、参与排序的权重等。
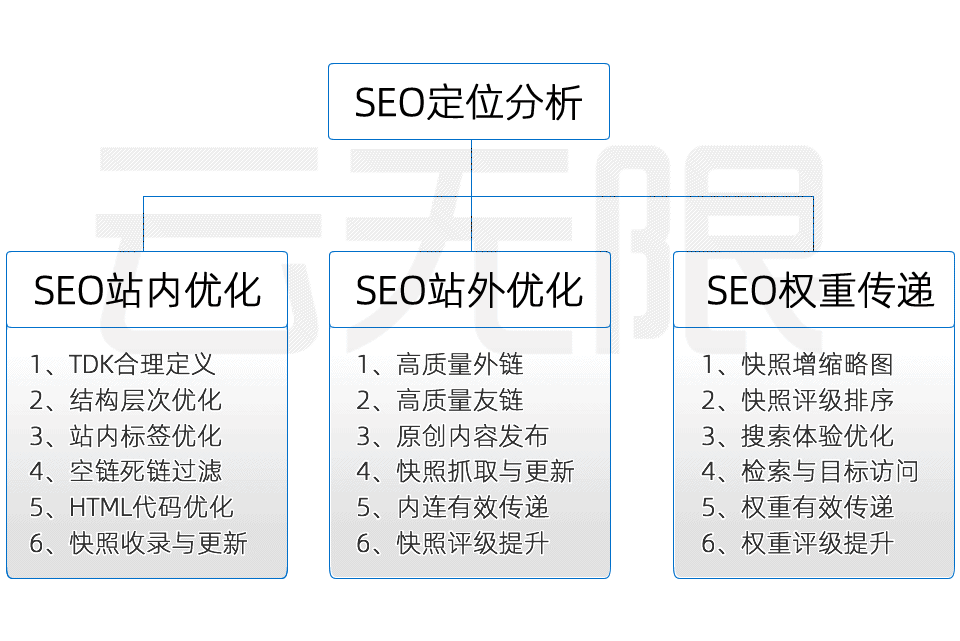
SEO策略


搜到你
让用户搜到你的网站是做SEO优化的目标,拥有精湛的SEO技术、丰富的经验技巧以及对SEO规则的深刻把握才有机会获得更好排名!

了解你
确保网站内容清晰、准确、易于理解,使用户能够轻松找到所需信息.使用简洁明了的标题和描述,帮助用户快速了解你的产品服务!

信任你
将企业的核心价值、差异化卖点、吸引眼球的宣传语等品牌词尽可能多的占位搜索前几页,增强用户印象,优化用户体验让访客信任你!

选择你
优化落地页引导用户咨询或预约留言,引用大型案例或权威报道彰显品牌实力,关注用户需求和反馈,不断优化产品服务让用户选择你!
关键词研究

品牌关键词
提升品牌知名度、塑造品牌形象,吸引对品牌感兴趣的用户,同时帮助监测品牌在搜索引擎中的表现。

核心关键词
是网站内容的主要焦点,能吸引大量目标受众,提高网站在相关搜索中的排名。搜索量大,竞争较激烈。

长尾关键词
更能够更精确地定位目标受众,提高转化率,竞争相对较小更容易获得排名,更符合用户的具体搜索意图。

区域关键词
针对特定地区进行优化,帮助本地企业吸引当地用户,提高本地市场的曝光度。适用于有地域性需求的企业。


竞品关键词
与竞争对手品牌或产品相关的词,通过分析这些关键词,可以了解竞争对手的优势和劣势。

产品关键词
直接针对产品进行优化,与具体产品或服务直接相关,如产品名称、型号、功能等描述性词汇。

搜索下拉词
反映用户的搜索习惯和需求,是搜索引擎根据用户输入自动推荐的词汇,与用户搜索意图高度相关。

相关搜索词
提供与主题相关的其他搜索词汇,帮助用户发现更多相关内容,同时扩展网站的优化范围。
站内SEO

TDK优化
力争一次性完成网站页面标题、描述、关键词的的合理部署

链接优化
包含LOGO链接、导航链接、文章链接及外部链接等SEO优化设置

HTML优化
HTML代码、标签等优化:H,alt,strong,title,span,title等标签

内容优化
固定内容与关键词SEO匹配、动态内容提升蜘蛛抓取率增强快照评级
站外SEO

1)降低文章内容在搜索结果的重合度。尤其是文章标题、段落主题、内容摘要等;
2)标题包含关键词(可包含部分或完整匹配)字数控制在24字内;
3)提炼的文章概要(100字内)必须与关键词有相关性才有意义;
4)新文章不要增加锚文本超链接,等文章快照有排名后再扩充锚文本链接;
5)文章内容与标题关键词相呼应,建立关联,也可根据关键词扩充有关的内容;
6)文章中的图片最好增加alt属性,图片不要失真和变形,宽度大于500px更优机会抢占搜索快照缩略图;
7)文章排版合理、段落分明、段落主题用H标签加强,段落内容用span或p标签区分;
8)发布文章后先引导收录。如提交搜索引擎登录、合理使用有排名快照的内部链接;
9)如果文章7天还没有收录,就要提升文章内容质量再发布;
